Python數(shù)據(jù)分析實(shí)戰(zhàn) 抓取課工廠網(wǎng)站數(shù)據(jù)、處理與存儲全流程解析
在數(shù)據(jù)驅(qū)動的時代,Python憑借其豐富的庫和簡潔的語法,已成為數(shù)據(jù)獲取、處理與分析的首選工具之一。本文將通過一個完整的實(shí)例,詳細(xì)介紹如何使用Python抓取“課工廠”網(wǎng)站的數(shù)據(jù),并進(jìn)行清洗、分析與存儲,構(gòu)建一套自動化數(shù)據(jù)處理與存儲服務(wù)。
一、項(xiàng)目目標(biāo)與準(zhǔn)備工作
本項(xiàng)目旨在從“課工廠”網(wǎng)站(一個假設(shè)的教育類網(wǎng)站,提供各類在線課程信息)上抓取課程數(shù)據(jù),包括課程名稱、講師、價格、評分、學(xué)習(xí)人數(shù)等關(guān)鍵信息。通過對這些數(shù)據(jù)進(jìn)行處理與分析,我們可以洞察課程市場的趨勢、熱門領(lǐng)域及用戶偏好。
準(zhǔn)備工作包括:
- 環(huán)境配置:安裝Python(建議3.7及以上版本)及必要的庫,如requests(用于網(wǎng)絡(luò)請求)、BeautifulSoup或lxml(用于HTML解析)、pandas(用于數(shù)據(jù)處理與分析)、sqlalchemy(用于數(shù)據(jù)庫操作)等。
- 目標(biāo)分析:手動瀏覽“課工廠”網(wǎng)站,分析其頁面結(jié)構(gòu)、URL規(guī)律及數(shù)據(jù)存放的標(biāo)簽,為編寫爬蟲程序奠定基礎(chǔ)。
- 法律與倫理:確保爬蟲行為遵守網(wǎng)站的robots.txt協(xié)議,并設(shè)置合理的請求間隔,避免對目標(biāo)網(wǎng)站造成過大負(fù)載。
二、數(shù)據(jù)抓取:構(gòu)建穩(wěn)健的爬蟲程序
數(shù)據(jù)抓取是第一步,我們使用requests庫發(fā)送HTTP請求,并利用BeautifulSoup解析返回的HTML頁面,提取所需的結(jié)構(gòu)化數(shù)據(jù)。
關(guān)鍵步驟:
- 模擬請求頭:設(shè)置User-Agent等頭部信息,模擬瀏覽器訪問,降低被反爬機(jī)制攔截的風(fēng)險。
- 分頁處理:分析課程列表頁的URL分頁規(guī)律(如
?page=1),通過循環(huán)遍歷所有頁面,確保抓取數(shù)據(jù)的完整性。 - 數(shù)據(jù)提取:針對每個課程詳情頁,定位并提取目標(biāo)數(shù)據(jù)字段。例如,課程名稱可能位于
<h1 class="course-title">標(biāo)簽內(nèi),價格信息可能在<span class="price">中。 - 異常處理與延時:添加try-except塊處理網(wǎng)絡(luò)異常或解析錯誤,并利用time.sleep()在請求間加入隨機(jī)延時,體現(xiàn)良好的爬蟲禮儀。
- 數(shù)據(jù)暫存:將每次循環(huán)抓取到的數(shù)據(jù)以字典形式存入列表,為后續(xù)處理做準(zhǔn)備。
示例代碼片段(僅展示核心邏輯):`python
import requests
from bs4 import BeautifulSoup
import time
import pandas as pd
baseurl = "https://www.kegongchang.com/courses"
datalist = []
for page in range(1, 11): # 假設(shè)抓取前10頁
url = f"{baseurl}?page={page}"
headers = {'User-Agent': 'Mozilla/5.0'}
try:
response = requests.get(url, headers=headers)
soup = BeautifulSoup(response.text, 'html.parser')
courses = soup.findall('div', class='course-item') # 假設(shè)的課程容器
for course in courses:
coursedata = {}
coursedata['title'] = course.find('h2').text.strip()
coursedata['instructor'] = course.find('span', class='instructor').text.strip()
coursedata['price'] = course.find('div', class_='price').text.strip()
# 更多字段提取...
datalist.append(coursedata)
time.sleep(1) # 禮貌延時
except Exception as e:
print(f"抓取第{page}頁時出錯: {e}")`
三、數(shù)據(jù)處理:清洗、轉(zhuǎn)換與豐富
抓取的原始數(shù)據(jù)往往存在缺失值、格式不一致等問題,需通過pandas進(jìn)行清洗和轉(zhuǎn)換,使其適合分析。
核心處理環(huán)節(jié):
- 創(chuàng)建DataFrame:將抓取的數(shù)據(jù)列表轉(zhuǎn)換為pandas DataFrame,便于后續(xù)操作。
- 數(shù)據(jù)清洗:
- 處理缺失值:使用
fillna()填充或dropna()刪除缺失數(shù)據(jù)。
- 格式標(biāo)準(zhǔn)化:例如,將價格字段從字符串(如“¥199”)轉(zhuǎn)換為數(shù)值類型,移除貨幣符號并轉(zhuǎn)換為浮點(diǎn)數(shù)。
- 去重處理:基于課程ID或標(biāo)題去除可能存在的重復(fù)記錄。
- 數(shù)據(jù)轉(zhuǎn)換與衍生:
- 分類標(biāo)簽:根據(jù)課程標(biāo)題或描述,提取關(guān)鍵詞或進(jìn)行分類(如“編程”、“設(shè)計”、“商業(yè)”)。
- 評分分段:將連續(xù)評分轉(zhuǎn)換為“高”、“中”、“低”等級別,便于分組分析。
- 數(shù)據(jù)驗(yàn)證:檢查處理后的數(shù)據(jù)分布與基本統(tǒng)計信息,確保數(shù)據(jù)質(zhì)量。
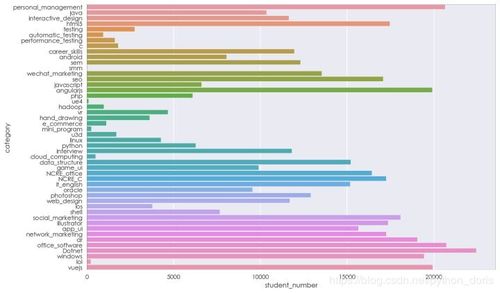
四、數(shù)據(jù)分析:挖掘洞察與可視化
利用pandas的數(shù)據(jù)聚合、分組功能,結(jié)合matplotlib或seaborn進(jìn)行可視化,我們可以從多個維度分析課程數(shù)據(jù)。
可能的分析方向:
- 總體概覽:統(tǒng)計課程總數(shù)、平均價格、平均評分等。
- 價格分析:計算不同類別課程的價格分布、中位數(shù)及高價/低價課程占比。
- 熱度分析:根據(jù)學(xué)習(xí)人數(shù)或評分,找出最受歡迎的課程及講師。
- 關(guān)聯(lián)分析:探索價格、評分、學(xué)習(xí)人數(shù)等變量間的相關(guān)性。
示例分析代碼:`python
import matplotlib.pyplot as plt
假設(shè)df為處理后的DataFrame
按課程類別統(tǒng)計平均價格
avgpricebycategory = df.groupby('category')['price'].mean().sortvalues()
繪制柱狀圖
avgpricebycategory.plot(kind='bar')
plt.title('各課程類別平均價格')
plt.xlabel('課程類別')
plt.ylabel('平均價格(元)')
plt.tightlayout()
plt.show()`
五、數(shù)據(jù)存儲:構(gòu)建持久化服務(wù)
分析完成后,需要將原始數(shù)據(jù)及處理結(jié)果持久化存儲,以便后續(xù)使用或集成到其他應(yīng)用中。常見的存儲方案包括:
1. 文件存儲:將DataFrame保存為CSV、Excel或JSON文件,便于分享與快速查看。
`python
df.tocsv('kegongchangcourses.csv', index=False, encoding='utf-8-sig')
`
2. 數(shù)據(jù)庫存儲:使用SQLAlchemy將數(shù)據(jù)存入SQLite、MySQL或PostgreSQL等關(guān)系型數(shù)據(jù)庫,便于復(fù)雜查詢與管理。
`python
from sqlalchemy import create_engine
# 創(chuàng)建SQLite數(shù)據(jù)庫引擎
engine = create_engine('sqlite:///courses.db')
# 將DataFrame存入名為'courses'的表
df.tosql('courses', engine, ifexists='replace', index=False)
`
- 云存儲或數(shù)據(jù)倉庫:對于大規(guī)模數(shù)據(jù),可以考慮上傳至云存儲(如AWS S3)或?qū)氲綌?shù)據(jù)倉庫(如Google BigQuery)中,支持更強(qiáng)大的分析能力。
六、服務(wù)化與自動化
為使整個流程可持續(xù)運(yùn)行,我們可以將上述步驟腳本化,并加入定時任務(wù)(如使用cron或APScheduler)實(shí)現(xiàn)定期自動抓取與更新。進(jìn)一步,可以封裝為簡單的Web服務(wù)(使用Flask或FastAPI),提供數(shù)據(jù)查詢接口,或生成自動化分析報告并通過郵件發(fā)送。
通過這個從抓取、處理、分析到存儲的完整案例,我們展示了Python在數(shù)據(jù)分析項(xiàng)目中的強(qiáng)大能力。它不僅幫助我們高效獲取網(wǎng)絡(luò)數(shù)據(jù),還能通過系統(tǒng)的處理與分析,將原始信息轉(zhuǎn)化為有價值的商業(yè)洞察。在實(shí)際應(yīng)用中,請務(wù)必根據(jù)目標(biāo)網(wǎng)站的具體結(jié)構(gòu)調(diào)整代碼,并始終遵守相關(guān)法律法規(guī)與道德準(zhǔn)則。
如若轉(zhuǎn)載,請注明出處:http://m.87lh.cn/product/58.html
更新時間:2026-05-29 18:45:28